EECS 675: Multicore and GPU Programming
In-Class Materials
Material may be added and/or edited throughout the semester.
I always try to have any such additions and edits posted
before the class in which they are first covered.
- Introductory architectural concepts
- EECS Servers
- Shared memory multiprocessor architectures for thread-level
(e.g., C++ std::thread) MIMD parallelism; Single address space
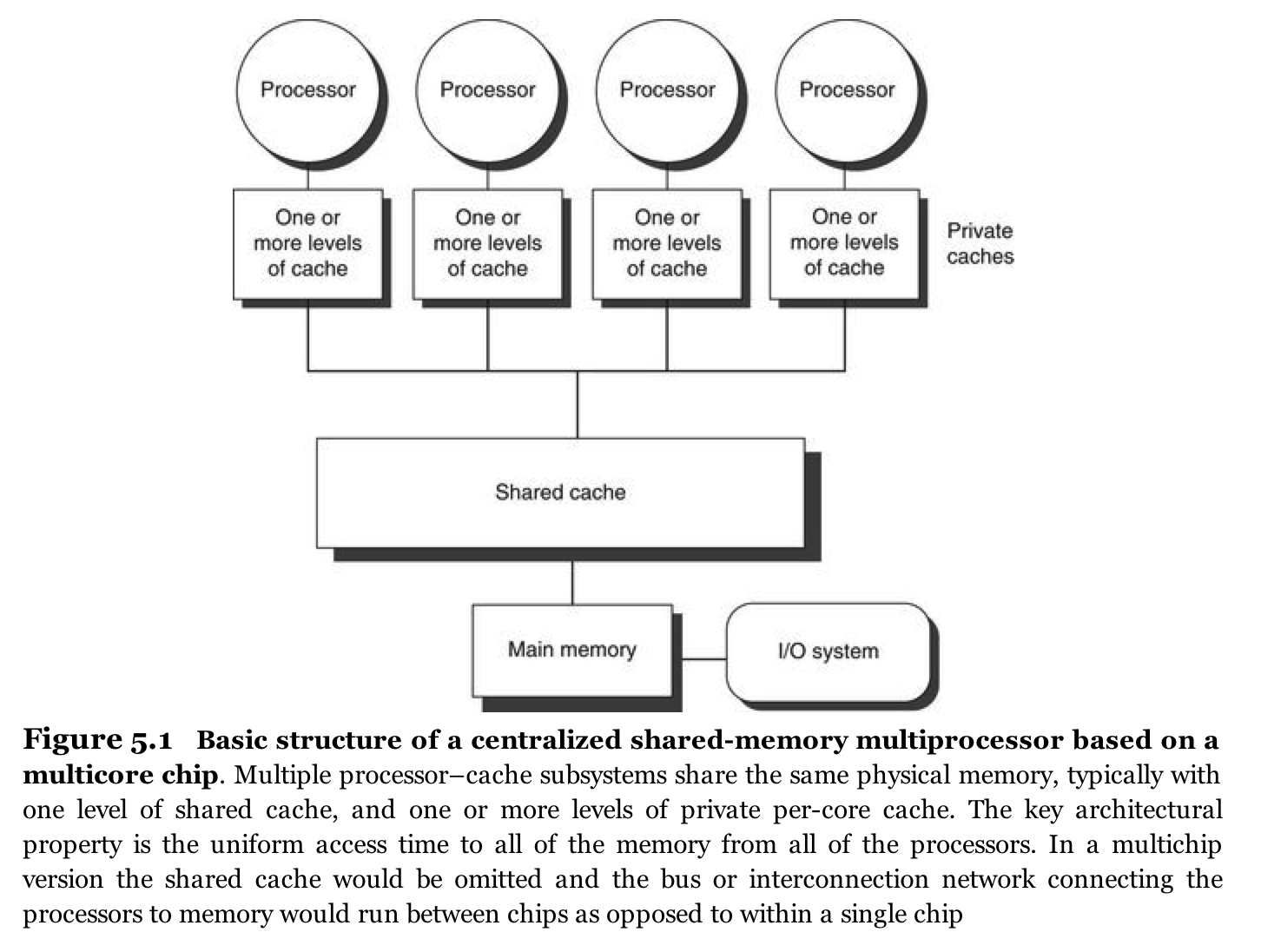
- Shared memory multiprocessors (SMPs) using Uniform Memory Access (UMA) (Figure 5.1 from Computer Architecture: A Quantitative Approach,
J. L. Hennessy and D. A. Patterson, Morgan Kaufmann, fifth edition, 2012.)
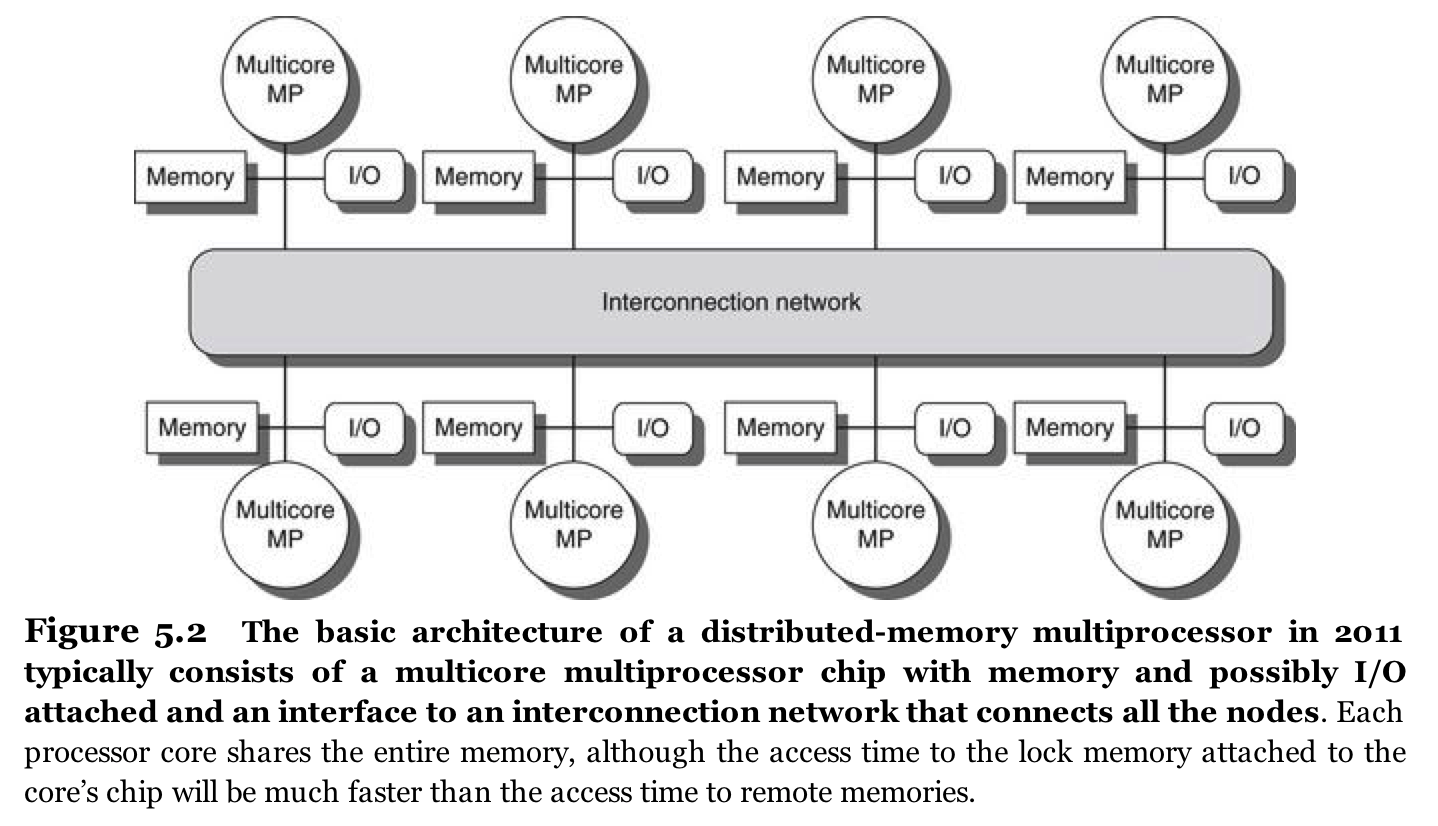
- Distributed shared memory multiprocessors (DSMs) using Nonuniform Memory Access (NUMA) (Figure 5.2 from Computer Architecture: A Quantitative Approach,
J. L. Hennessy and D. A. Patterson, Morgan Kaufmann, fifth edition, 2012.)
- Distributed Memory MIMD ("shared nothing"); Multiple address spaces
- A networked collection of machines programmed using, for example, OpenMPI.
- GPU SIMD
- Programmed using, for example, CUDA or OpenCL.
- Basic shared memory multi-threaded programming (Barlas, Chapter 3)
- API References
- Some basic examples of using std::thread
- Listing 3.2 illustrating the use of
std::thread
- InitializeArray.c++
- Listing 3.2
modified to create an arbitrary number of child threads, each with a unique "work assignment"
- Listing 3.2
further modified to avoid garbled output by allowing only one thread to produce output. (We
will see a more satisfying way to prevent garbled output shortly.)
- Listing 3.2
modified one more time to introduce thread IDs.
- Threads accessing global variables
- Retrieving results
from a thread
- Programmer-defined classes with threads
- Using binary semaphores (C++'s std::mutex) to control access
to shared resources
- Interim Summary: Code and Memory in multi-threaded applications
- Unique locks:
Listing_3_2_WithWorkAssignment_unique_lock.c++
- The Monitor Design Pattern. Two examples:
- On starting all threads at once:
- Multicore programming: MIMD/Distributed Memory ("Shared Nothing") (Barlas, Chapter 5 – not Chapter 4)
- Processes can only communicate via explicit message passing
- The Message
Passing Interface (MPI) standard (specification for the API; not a language)
- MPI Forum: the standardization forum for the Message Passing Interface (MPI)
- OpenMPI: One of the most common
implementations of the MPI standard
- Documentation
(Select the version you want – eecs is running 2.1.1 as of Spring 2020 –
to see man pages for (i) compiling and running,
(ii) individual Open MPI function specifications.)
- Basic OpenMPI Examples
- Buffering and Blocking in Point-to-Point OpenMPI Message Passing
- Buffered; locally blocking (sender only; MPI_Bsend)
- Synchronous; globally blocking (sender only; MPI_Ssend)
- Ready; receiving process must have already initiated a receive (sender only; MPI_Rsend)
- Immediate; non-blocking (can be sender and/or receiver; MPI_Isend, MPI_Irecv)
- Summary: Basic
MPI Message Passing Primitives
- mpiMatrixMult.c++
- Using several message passing strategies (immediate and blocking) to perform a general matrix multiplication of
two non-square matrices.
- Be sure to note and understand:
- Where blocking send/receive requests are used versus where immediate
versions are used, and why.
- The code does not check all the MPI_Request objects for synchronization purposes. Why?
- The importance of the tags in the messages.
- Collective Message Passing in OpenMPI
- All to All Gathering and Scattering
- Summary: Collective
MPI Message Passing Primitives
- Programmer-Defined Data Types
- Groups and Communicators
- I/O
- Console input restricted to one rank process
- File I/O subsystem for shared R/W access to binary files
- Combining multi-threading with OpenMPI
- GPU programming (Barlas, Chapter 6)
- References
- General:
- Chapter 6 of: Multicore and GPU Programming: An Integrated Approach, Gerassimos Barlas,
Morgan Kaufmann, 2015.
- CUDA:
- NVIDIA CUDA site
- Programming Massively Parallel Processors, David B. Kirk & Wen-mei W. Hwu, Morgan-Kaufmann.
- OpenCL
- Khronos site
- Heterogeneous Computing with OpenCL, B. R. Gaster, L. Howes, D. R. Kaeli, P. Mistry, and
D. Schaa, Morgan-Kaufmann.
- GPU Terminology: Comparing OpenCL and CUDA
terms with those of Hennessy & Patterson
- Example GPU Architectures
- Comparing CUDA and OpenCL Thread Geometry conventions
- DAXPY: A quick CUDA-OpenCL comparison – (see also assignment of a similar kernel to GPU)
- Examples with complete CUDA and OpenCL implementations
- Simple OpenCL – illustrate OpenCL's platform model
- Hello
- DAXPY: Full implementation
- Matrix multiplication: C = A * B
- Useful utilities:
- CUDA
- helper_cuda.h: includes (see matrixMultiplyV3.cu for examples of use)
- function checkCudaErrors(cudaError_t err): (if err!=CUDA_SUCCESS, then
the text description of the error and the current file and line number are printed.)
Typical usage: Call this following CUDA API calls that return a cudaError_t value.
- function getLastCudaError(const char* msgTag) (calls cudaGetLastError(); if
result!=CUDA_SUCCESS, the current file and line number are printed followed by your supplied
msgTag followed by the text description of the CUDA error.)
Typical usage: Call this following CUDA calls such as kernel launches that do not provide a
cudaError_t result variable.
- helper_string.h (required by previous)
- To use:
- Save these two header files in your project directory.
- Add:
INCLUDES += -I.
to your Makefile.
- OpenCL
- OpenCL error code listings can be found in many places, for example:
here.
- An intermediate summary: Work Grid Size Determination
- Case Study: 2D Contouring
- Exploiting GPU Memory Hierarchy and Access
- Barlas' Histogram Example (section 6.6.2)
- Converted to OpenCL
- The test image
- Performance Optimization
- High-level work decomposition
- 1D/2D/3D computational grid design
- Configuring Kernel launch parameters
- Kernel Design
- Memory Management and Usage
- Asynchronous Kernel Launches
- Events
- Advanced topics
- Kernel timing and profiling
- Launching kernels from the GPU
- CUDA: Dynamic Parallelism (requires compute capability ≥ 3.5)
- OpenCL: Device-side queues and Device-side enqueueing (Requires OpenCL 2.0 and GPU support)
- nvvp: The NVIDIA Visual Profiler
- OpenCL Pipes
- Access
{kind=link}
{kind=link}
{kind=link}