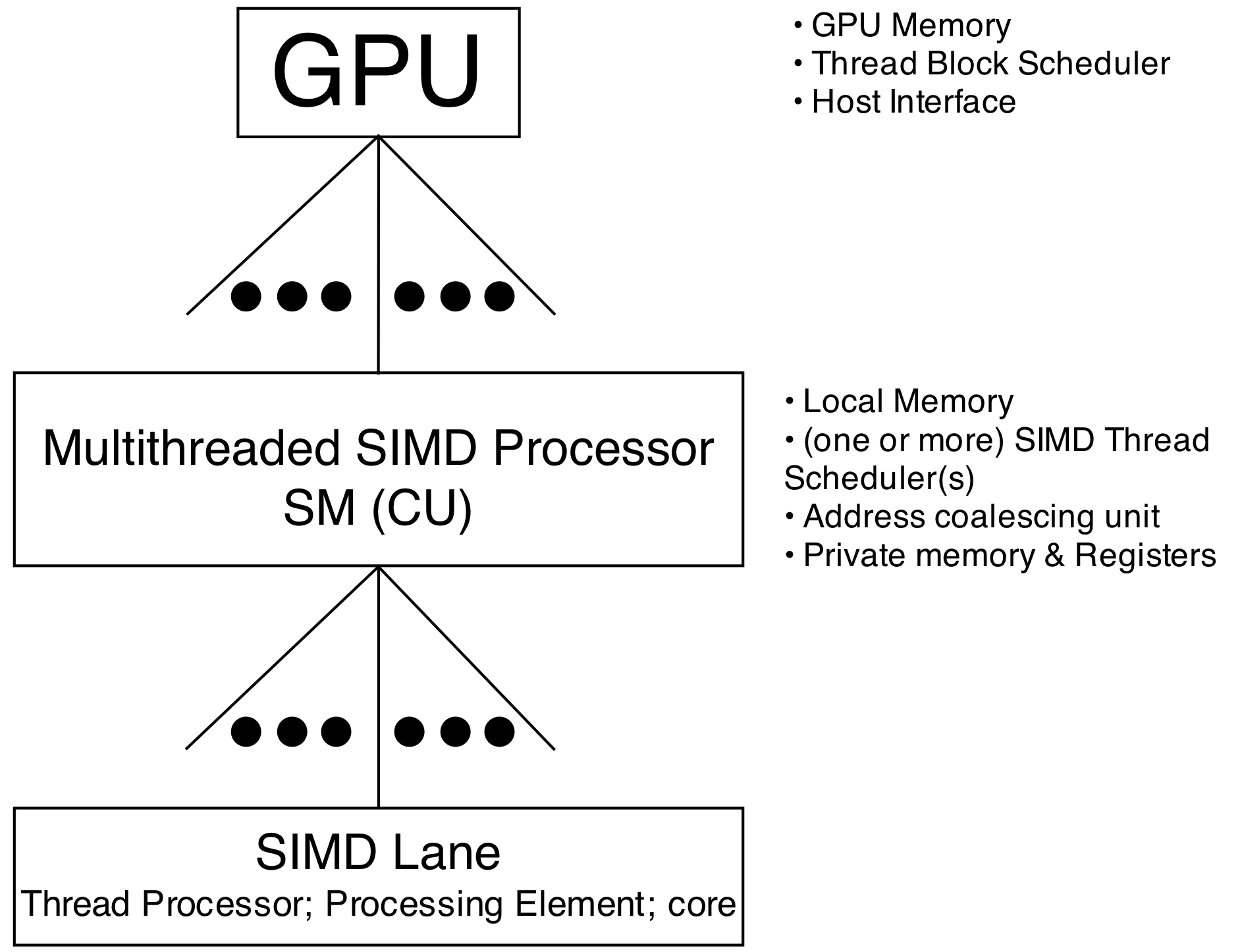
Different authors and different vendors use different terminology for common concepts related to GPU programming. Here we present the terminology from three particularly important sources: the well-known Hennessy & Patterson computer architecture text, the CUDA terminology you will see in NVIDIA publications, and the OpenCL terminology.
The general structure of the tables presented here was derived from Computer Architecture: A Quantitative Approach, J. L. Hennessy and D. A. Patterson, Morgan Kaufmann, 5th edition, 2012 (hereafter referred to as CAAQA). Specifically, section 4.4 and Figures 4.12, 4.24, and 4.25 of CAAQA were used as a guide.
There will of necessity be forward references in the tables below. If you encounter a term and haven't yet seen its definition, it is likely defined later. Several terms are listed in the "Definition" column as "CUDA term (OpenCL term)", where the two terms describe the same concept. For example: "Streaming Multiprocessor (Compute Unit)". Abbreviations are also used. For example: "SM (CU)".
| NVIDIA CUDA term | AMD and/or OpenCL term | CAAQA term | Definition |
| Grid | NDRange or index range | Vectorizable Loop | The overall computational grid presented by the CPU to the GPU for execution. It can be 1D, 2D, or 3D. It will be partitioned into an integral number of Thread Blocks (Work Groups). |
| Thread Block | Work Group | Body of Vectorized Loop | A subset of the computational
grid that will be assigned to a single Streaming Multiprocessor (Compute Unit). Like the grid (NDRange) of which it
is a part, the TB (WG) can be 1D, 2D, or 3D. There will be an integral number of TBs (WGs) spanning each
dimension of the grid (NDRange). Individual threads of a TB (WG)
can cooperatively utilize on-chip Shared Memory (Local Memory).
For execution purposes, TBs (WGs) will be partitioned into an integral number of warps (wavefronts). |
| CUDA Thread | Work Item | Sequence of SIMD Lane Operations | An individual thread of execution on a Streaming Multiprocessor (Compute Unit). |
| NVIDIA CUDA term | AMD and/or OpenCL term | CAAQA term | Definition |
| Warp | Wavefront | A Thread of SIMD Instructions | A group of threads that operate in SIMD lockstep fashion on a Streaming Multiprocessor (Compute Unit). The size of a Warp (Wavefront) is hardware-dependent. On most of today's GPUs, this size is 32 threads (work items). Each thread has an associated mask or predicate that controls whether it currently is allowed to alter memory. |
| PTX instruction | AMDIL or FSAIL | SIMD Instruction | A single instruction. |
| NVIDIA CUDA term | AMD and/or OpenCL term | CAAQA term | Definition | |
| Streaming Multiprocessor (SM) | Compute Unit (CU) | Multithreaded SIMD Processor | The portion of the GPU on which the warps (wavefronts) of one or more thread blocks (work groups) execute. It typically includes single and double precision cores, special function units, registers, and shared (local) memory. The entirety of a TB (WG) will be assigned to a single SM (CU). | |
| Giga Thread Engine | Ultra-Threaded Dispatch Engine | Thread Block Scheduler | Assigns TBs (WGs) to SMs (CUs). Resides at the top level of the GPU. | |
| Warp Scheduler | Work Group Scheduler | SIMD Thread Scheduler | A scheduler that controls the actual execution of warps (wavefronts) on collections of cores and associated special function units. There will be one or more of these schedulers on each SM (CU). | |
| Thread Processor (core) | Processing Element (core) | SIMD Lane | The hardware on which individual threads of instructions are executed. Collections of N cores – where N is the size of the warp (wavefront) – share an instruction counter and execute the threads of the warp (wavefront) in SIMD fashion. |
| NVIDIA CUDA term | AMD and/or OpenCL term | CAAQA term | Definition | 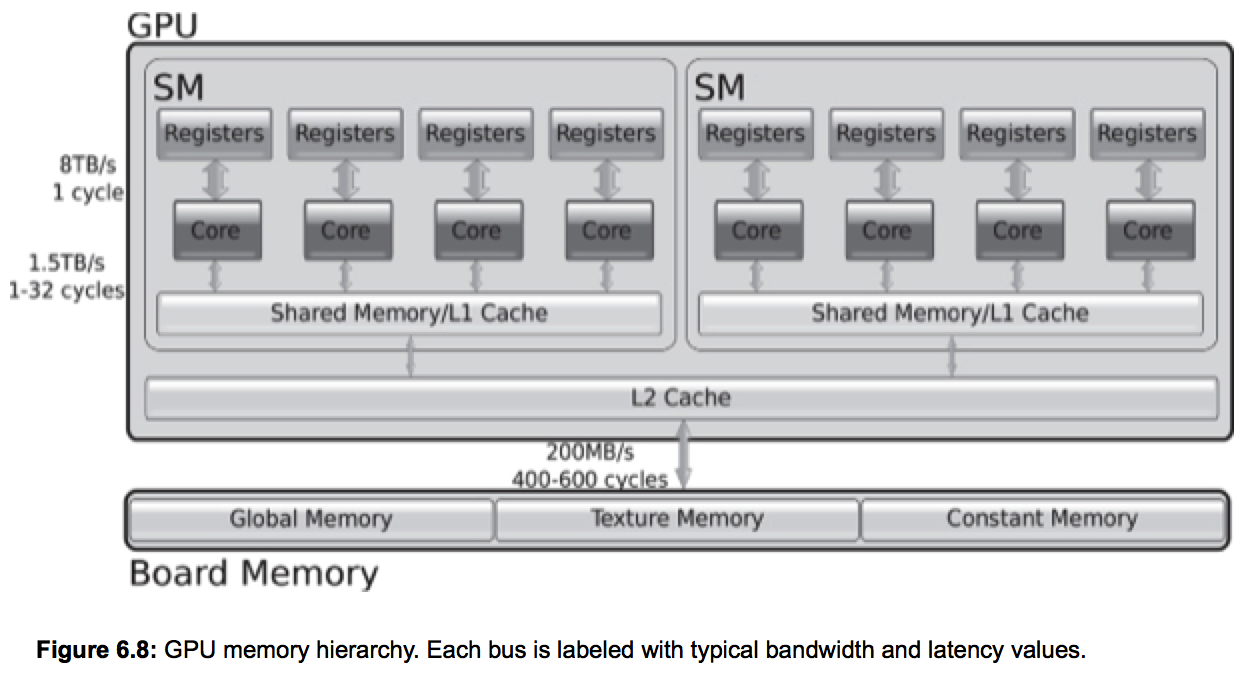 source: Multicore and GPU Programming: An Integrated Approach, G. Barlas, 2015 |
| Global Memory | Global Memory | GPU Memory | Memory on the GPU accessible by all
SMs (CUs) in the GPU. This global memory is fairly large, but much slower to access
than the shared (local) on-chip memory in the SMs (CUs).
(Note especially: global, texture, and constant.) |
|
| Shared Memory | Local Memory | Local Memory | Fast local memory placed on-chip inside each SM (CU). This memory is smaller than global memory, much faster, and available only to threads belonging to a Thread Block (Work Group) assigned to the SM (CU). | |
| Registers | Registers | Registers | Registers – located on the Thread Processor (CUDA), Processing Element (OpenCL), or SIMD Lane (CAAQA) – used to hold stack-allocated variables for a single thread. (See also next row of terms.) | |
| Local Memory | Private Memory | Private Memory | Memory used to hold stack-allocated variables for a single thread. Documentation suggests that such stack-allocated variables that cannot be accommodated by the number of registers allocated to a single thread are stored off-chip in Global Memory. Documentation also suggests that many of these variables will often be resident in the L2 cache on the SM (CU) chip. |